How rel=nofollow Works
2012-01-12
There has been a furious storm around Google’s new Search, Plus Your World features. The hubbub is centered around a complaint by Twitter that links shared on Twitter are not surfacing in the search results.
Google responded on Google+ with a terse statement:
We are a bit surprised by Twitter’s comments about Search plus Your World, because they chose not to renew their agreement with us last summer (http://goo.gl/chKwi), and since then we have observed their rel=nofollow instructions.
Before ascribing evil motives to Google, it’s important to understand exactly what rel=nofollow does, and how Twitter is currently using it. The rel=nofollow attribute is placed inside the HTML link tag. It’s an anti-spam measure that tells the Googlebot to not follow the link when crawling the Web. So <a href="http://example.com" rel="nofollow'>Click here</a> will be rendered as a clickable link to the user, but the Googlebot will not follow the link as it is crawls the web page containing that link.
Twitter.com incorporates rel=nofollow in all outbound links contained in tweets, most likely in an effort to deter spammers. The HTML for a tweet on Twitter.com looks something like this:
<div class="tweet">Check out this link: <a href="http://t.co/123"
rel="nofollow">http://t.co/123</a></div>
This means that while the Googlebot will index the text of the tweet, it will not follow any link in that tweet. Thus, Google will never know what a particular tweet links to because Twitter explicitly told it not to follow any links.
So Google launches Search Plus, and we start to see results that indicate that “John Doe shared this on Some Site”:
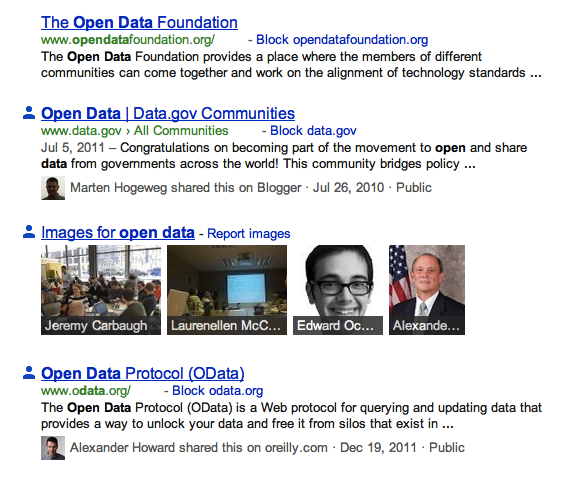
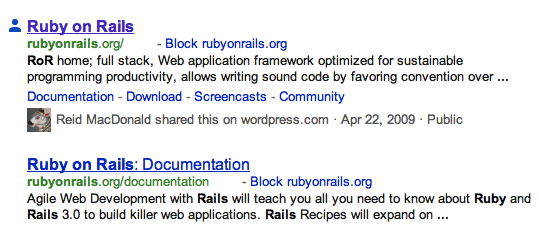
But we’ll never see “Jane Smith shared this on Twitter” because Twitter uses rel=nofollow on all outbound links in tweets. So even if @JaneSmith shared a relevant link, Twitter explicitly told Google not to index that link. Google will still index the text of the tweet. But without knowing what link the tweet points to, Google has no way inform us that a link was shared on Twitter.
It’s frustrating to see tech pundits severely misinterpret the facts and come to false conclusions. Here’s Danny Sullivan, who’s an expert on this stuff:
My take is that Google, by mentioning this in its post, is trying to suggest that Twitter is hurting itself by blocking its own pages using nofollow.
That’s clearly not what Google is saying. This has nothing to do with pages on Twitter.com. Twitter is telling Google to not index (outbound) links in tweets, and Google is complying. The consequence is that a link shared on Twitter will never be known to Google, and won’t be displayed.
MG Siegler perpetuates the misinterpretation:
But even more interesting is what Google said after blaming Twitter for Google screwing them: “since then we have observed their rel=nofollow instructions.” It’s subtle, but it sure sounds like Google is implying that they’re no longer crawling twitter.com — at Twitter’s request — so they don’t have the access needed to include Twitter in Search+.
But that doesn’t actually mean this at all. Sullivan also points this out in his post and also notes that it sounds like bullshit misdirection. All it means is that in some cases, Google won’t follow links from and to twitter.com. But as Sullivan notes, Google has over 3 billion Twitter pages in their index.
Once again, this is completely off the mark and insinuates all sorts of bad intention. Google is simply complying with Twitter.com’s directive to not follow outbound links in tweets it crawls, and the consequence is that there will never be “… shared this on Twitter” in the search results.
The same issue would affect any website that chooses to put rel=nofollow on all its outbound links. Usually the directive is used in places like the comments section of a blog post (to deter spam), but Twitter has decided to use it for all tweets. There is no great conspiracy against Twitter here. Google is simply following the rules of rel=nofollow.